haisql_memcache流程介绍
一、haisql_memcache整体流程
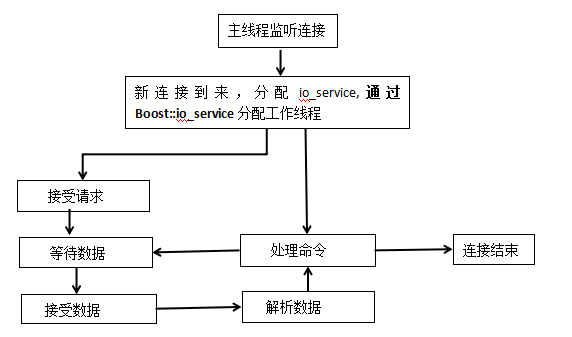
haisql_memcache的整体结构采用的是多线程框架,并且haisql_memcache的多线程框架采用的是一对多的策略,其中主线程主要用来监听新的网络连接,工作线程用来处理请求,主线程和工作线程是通过socket实现的,在每个请求的过程中,请求以及响应的过程都是通过一个状态来实现的,当有连接连接上来的时候,主线程会将连接交个某一个工作线程去接管,后期客户端和服务端的读写工作都会在这个工作线程中进行。
haisql_memcache整体运转流程图如下:
二.haisql_memcache操作流程
流程图如下:

流程图说明:
1:检查客户端的请求数据是否在haisql_memcache中,如有,直接把请求数据返回,不再对数据库进行任何操作,路径操作为①②③⑦。
2.如果请求的数据不在haisql_memcache中,就去查数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到haisql_memcache中(haisql_memcache客户端不负责,需要程序明确实现),路径操作为①②④⑤ ⑦⑥。
3.每次更新数据库的同时更新haisql_memcache中的数据,保证一致性。
4.当分配给haisql_memcache内存空间用完之后,会根据给数据设置的过期时间,进行管理缓存的数据,当检测到数据过期时,即数据老化,会自动删除这些老化了的数据,而需要永久保存的数据则不会被清理,不会造成数据的丢失,以此来管理内存空间。
三、haisql_memcache工作原理
首先haisql_memcache是以守护程序方式运行于一个或多个服务器中,随时接受客户端的连接操作。
客户端在与haisql_memcache服务建立连接之后,接下来的事情就是存取对象了,每个被存取的对象都有一个唯一的标识符key,存取操作均通过这个key进行,保存到haisql_memcache中的对象实际上是放置内存中的,并不是保存cache文件中的,因此haisql_memcache能够高效快速处理数据。
haisql_memcache采用了C/S的模式,在server端启动服务进程,在启动时可以指定监听的ip、自己的端口号,所使用的内存大小等几个关键参数。一旦启动,服务就一直处于可用状态。
haisql_memcache的多个Server可以协同工作,但这些 Server 之间是没有任何通讯联系的,每个Server只是对自己的数据进行管理。Client端通过指定Server端的ip地址(通过域名应该也可以)。需要缓存的对象或数据是以key->value对的形式保存在Server端。key的值通过hash进行转换,根据hash值把value传递到对应的具体的某个Server上。当需要获取对象数据时,也根据key进行。首先对key进行hash,通过获得的值可以确定它被保存在了哪台Server上,然后再向该Server发出请求。Client端只需要知道保存hash(key)的值在哪台服务器上就可以了。
1.haisql_memcache工作原理如图所示:
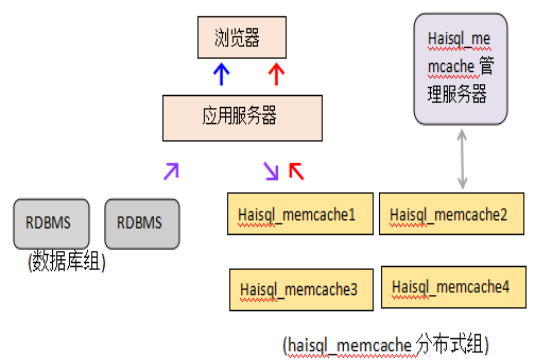
→第一次访问:先从RDBMS中取得数据保存到haisql_memcache中;
→第二次后:从haisql_memcache中取得数据显示在页面中。
haisql_memcache管理服务器职责:
监控haisql_memcache资源状态,监控对象命中率及有效性,haisql_memcache crash后会显示警告信息,当某一缓存节点出现问题,通知应用程序从其他的缓存服务器读取数据,从而提高可用性。
2.1特征
协议简单
它是基于文本行的协议,直接通过telnet在hasiql_memcache服务器上可进行存取数据操作。
内置内存存储方式
通过给数据设置过期时间,来管理缓存的数据,当检测到数据过期时,即数据老化,会自动删除这些老化了的数据,从而来管理数据库内部存储的数据,重启电脑时,会删除缓存的的数据。
haisql_memcache分布式
各个haisql_memcache服务器之间互不通信,并且各自独立存取数据,不共享任何的信息。服务器本事并不具有分布式的功能,分布式的部署完全取决于haisql_memcache客户端。
2.2原理
haisql_memcache采用动态空间分配,将数据库分为32个表,再将每个数据表分为256个组,保存的数据会存储在其中一个组里,同时会根据要存储的数据的大小自动进行内存的分配,当要保存大量的数据信息时,haisql_memcache便会自动扩展内存,而当要保存的数据很少时,会自动减少内存空间的分配,这样便大大减少了内存的占用率。同时haisql_memcache中,用户可以设置数据老化的时间,当设置老化时间为0时,表示数据会永久保存。


 新公网安备 65010502000200号
新公网安备 65010502000200号